Are metaphors wormholes for language models? My first encounter with SAE Analysis
I recently wrote an essay on why the human mind is not a computer. It is not that the analogy is completely incorrect, but it is not exhaustive. The mind cannot be detached from the body, and this is evident in the way we think and perceive the world. Our thinking is embodied, spatial, and metaphorical.
According to Cognitive Metaphor Theory (Lakoff & Johnson), human thinking is, in a sense, layered. At the bottom are concrete experiences and observations, along with the concrete thoughts associated with them; all abstract thinking is built upon this foundation. These different layers of thinking – levels of abstraction – are connected to one another through metaphors. A metaphor connects two things, the concrete and the abstract, thereby helping to better perceive the abstract concept.
Although there are decisive differences in the functioning of the human mind and the machine mind – artificial intelligence – there are also similarities. This led me to ponder the creativity of AI. Language models occasionally make “creative leaps,” recognizing connections between distinct concepts that are far apart. This has been explained, among other things, by the temperature setting, which I understand affects how strictly the language model adheres to probability limits. But what is the actual mechanism by which the language model executes these wilder twists and leaps?
Because AI fascinates me so much, I have been trying to learn to understand its operating principles. I already knew that transformer language models process information in layers and that the level of abstraction increases with the layers. Then it occurred to me: What if metaphor is also the infrastructure of the language model’s “thinking”?
Language models are trained on language used by humans. What if it doesn’t just learn words and linguistic structures, but also recognizes the structures of thought crystallized within the language? Human thinking has evolved to optimize energy usage. I assume metaphors are efficient in this regard as well. Perhaps the model has determined that it pays to utilize these structures – transferred along with the language – for storing (compressing) information and navigating within it?
(At this point, my own mind took a rather wild leap, and I began to imagine metaphors—especially metaphorical verbs – as if they were wormholes through which one can take a shortcut to the other side of the galaxy… or at least to another domain. Engage! 😉)
One thing led to another, and soon I found myself on a site called Neuronpedia, digging into the SAE features of Google DeepMind’s Gemma-2-2B language model. These are the “auxiliary structures” of a language model that reveal how the model activates based on words and sentences – in other words, they help us understand how the language model “thinks.”
This activation can be viewed and tested with Neuronpedia’s Sparse Auto-Encoder (SAE) tool, which is itself a small neural network. It was developed to reveal and separate overlapping internal meanings within a language model – like untying knots where multiple “thoughts” travel along the same route. This can be problematic if the model does not properly recognize what is currently being discussed, increasing the risk of errors and hallucinations.
In a recent study, Wang et al. (2025) aimed to improve model performance specifically using SAE technology. In this setup, language ambiguity and metaphors are essentially a problem – an error or disturbance in the model’s logic that needs to be resolved.
I, of course, was and am interested in metaphors from a different perspective. Although, if we think about the wormhole analogy, it is indeed problematic if one ends up in a wormhole by accident and, after arriving on the other side, no longer knows how to continue!
I used Neuronpedia’s Search by Inference function to look for interesting SAE features. I tested the activation of features with example sentences where the same verb appears in either a concrete or a more figurative, less literal sense.
I must emphasize that this was my very first contact with the Mechanistic Interpretability of language models. I was learning to understand while doing it, and even afterwards. Gemini served as my guide and interpreter in this process. In other words, there may be errors and misunderstandings, and the interpretations below should be read as the speculations of an enthusiastic language person. In any case, that experiment was a very interesting learning journey!
I used the following test sentences to see how the language model activates for the verb flow:
- The water flows in the river.
- Money flows into my bank account.
- Information flows through the internet.
- Traffic flows along a city road.
In addition, I ended up testing the verb travel when I noticed that the SAE feature I selected also activated for it:
- The train travels across the country.
- Ideas travel across cultures.
- Electricity travels through wires.
- Memory travels back to childhood.
I was looking for SAE features that would indicate how the language model processes the verb flow as changes in state. I found such features with relative ease. By testing those different example sentences, I found and selected the following SAE features. They are from different layers – transformer language models process information in layers, and it is known that the level of abstraction in processing increases with the layers.
- Feature 15915, layer 19: Actions and processes that indicate movement or physical interaction
- Feature 16262, layer 22: Action-oriented verbs related to movement or travel
- Feature 8561, layer 23: Actions related to movement and travel
- Feature 5470, layer 24: Sequences of actions involving movement or travel
- Feature 6163, layer 25: Descriptive actions and movements within a narrative context
The table below shows the values representing the intensity with which each test sentence activated the feature in question.
| SAE Feature / Verb tested | 15915 (L19) | 16262 (L22) | 8561 (L23) | 5470 (L24) | 6163 (L25) |
| Water flows | 35.25 | 40.50 | 54.50 | 67.00 | 54.25 |
| Money flows | 36.25 | 0.00 | 20.13 | 33.25 | 27.25 |
| Information flows | 24.88 | 16.25 | 18.63 | 33.50 | 28.25 |
| Traffic flows | 19.88 | 33.25 | 32.25 | 38.75 | 41.00 |
| Train travels | 29.00 | 59.50 | 84.00 | 92.50 | 87.50 |
| Ideas travel | 28.13 | 33.00 | 43.50 | 49.25 | 53.50 |
| Electricity travels | 30.25 | 68.00 | 79.00 | 80.50 | 92.50 |
| Memory travels | 25.38 | 36.25 | 39.00 | 44.25 | 52.00 |
Layer 19 recognizes fundamental forces of physics?
The first relevant layer for this test seemed, at a quick glance, to be layer 19, where the model used SAE feature number 15915. Insofar as anything can be said from such a small sample, in this layer the model seems to recognize the fundamental forces of movement and physical interaction on a general level. There appears to be no difference in activation between the concrete and the figurative.
The sentences “Water flows” (35.25) and “Money flows” (36.25) activate this Feature with almost the same intensity; likewise “Train travels” (29.00) and “Ideas travel” (28.13). The model’s interpretation is likely something along the lines of: “Something is moving here, be it water or currency, vehicles or information.”
Additionally, the “positive logits” here were words like back, forward, up, down. Logits are words the model predicts as the next word. These reinforce the idea that this is specifically about movement and direction.
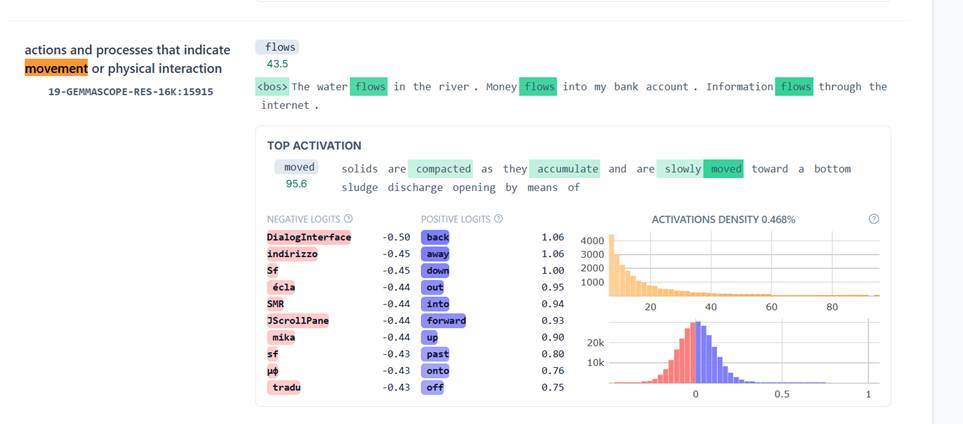
(Screenshot from Neuronpedia. In this image, I was testing several “flow” sentences at the same phrase. The values in the table above are from a test round where I tested one sentence at a time.)
Higher layers begin to distinguish the abstract from the concrete?
Moving to the higher layers, it appears that the concrete or literal interpretation activates the selected feature with roughly double the intensity compared to the abstract or figurative interpretation. The differences are strongest in layer 24. Both are perceived as movement, but the concrete one more strongly. Interesting!
One fun side observation from the experiment is electricity. The sentence “Electricity travels” seems to be more like a train (concrete) to the model than like an idea (abstract). The activation values for electricity rise consistently and peak in layer 25 at a value of 92.50 – even higher than for the train. One can thus surmise that for AI, electric current is very much a physical reality, not an abstraction.
In layer 24, Gemini hinted to look at the Logit section as well. Logits are words the model predicts as the next word. When feature 5470 activates, the model’s logits – its predictions for the next word – begin to emphasize cardinal directions: north, south, east, west. This seems to happen even when the subject of the sentence is abstract.
Inevitably, the thought arises: Is it possible that the model uses some kind of spatial simulation to perceive change even on a conceptual level? This would be very Lakoffian: abstract understanding is built upon the perception of concrete space. Of course, if those predictions are purely statistical, such an interpretation cannot be made based on them alone.
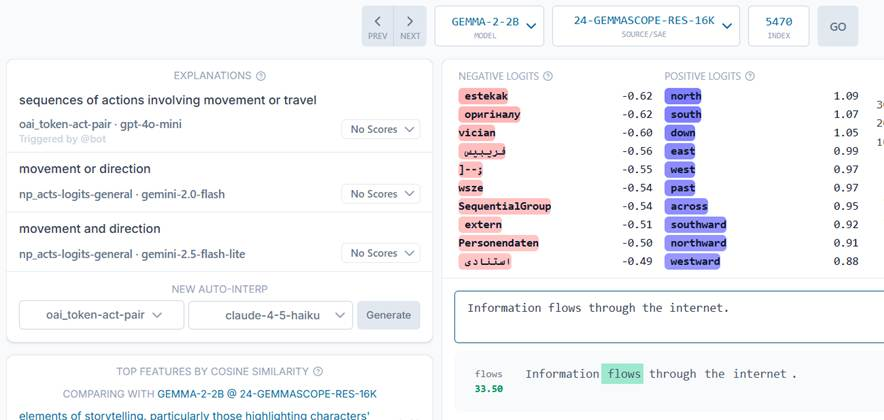
(Screenshot from Neuronpedia. The model’s predictions for the next word are shown in purple.)
Update (January 6): Right after publishing this, I discovered Gurnee and Tegmark’s study Language Models Represent Space and Time. They state: ”While further investigation is needed, our results suggest modern LLMs learn rich spatiotemporal representations of the real world and possess basic ingredients of a world model.” So, at least regarding concrete matters, the language model apparently does perform this kind of spatial simulation.
Reflection
As stated, this was just an experiment. Still, it seems to me that SAE analysis is not just a tool for reducing hallucinations, but has the potential to reveal the machine’s ways of structuring language and the world contained within language.
Another wild thought: Perhaps AI is not purely a “stochastic parrot.” Perhaps it has inherited, along with language, at least part of our world model, where both physical and abstract things obey the same laws of physics.
I haven’t found existing research on this specific matter yet. Do you know of any?