Ovatko metaforat kielimallille madonreikiä? Ensikosketukseni SAE-analyysiin
Kirjoitin äskettäin esseen siitä, miksi ihmismieli ei ole tietokone. Ei niin, etteikö tuo analogia pitäisi missään suhteessa paikkansa. Tyhjentävä se ei kuitenkaan ole. Mieltä ei voi irrottaa kehosta, ja se näkyy tavassamme ajatella ja hahmottaa maailmaa. Ajattelumme on kehollista, spatiaalista, metaforista.
Kognitiivisen metaforateorian (Lakoff ja Johnson) mukaan ihmisen ajattelu on tavallaan kerroksittaista. Pohjalla ovat konkreettiset kokemukset ja havainnot ja niihin liittyvät konkreettiset ajatukset, ja kaikki abstraktimpi ajattelu rakentuu niiden päälle. Nämä ajattelun eri kerrokset eli abstraktiotasot ovat kytköksissä toisiinsa metaforien eli vertauskuvien kautta. Metafora yhdistää kaksi asiaa, konkreettisen ja abstraktin, ja auttaa näin hahmottamaan abstraktia asiaa paremmin.
Vaikka ihmismielen ja konemielen – siis tekoälyn – toiminnassa on ratkaisevia eroja, niissä on myös samankaltaisuutta. Johduinkin miettimään tekoälyn luovuutta. Kielimallit tekevät välillä ”luovia loikkia” – tunnistavat yhteyksiä kaukanakin olevien konseptien välillä. Tätä on selitetty muun muassa temperature-säädöllä, joka käsittääkseni vaikuttaa siihen, miten tiukasti kielimalli pysyttelee todennäköisyyksien rajoissa. Mutta mikä on se mekanismi, jolla kielimalli niitä villimpiä käänteitä ja hyppyjä tekee?
Koska tekoäly kiehtoo minua niin paljon, olen hiukan yrittänyt opetella ymmärtämään sen toimintaperiaatteita. Tiesin ennestään, että transformer-kielimallit käsittelevät informaatiota kerroksittain ja että abstraktiotaso kasvaa kerrosten myötä. Ja sitten tuli mieleen: jospa metafora on myös kielimallin ”ajattelun” infrastruktuuri?
Kielimallit koulutetaan ihmisen käyttämällä kielellä. Entä jos se ei opi vain sanoja ja kielellisiä rakenteita, vaan se tunnistaa myös kieleen kiteytyneet ajattelun rakenteet? Ihmisen ajattelu on kehittynyt optimoimaan energian käyttöä. Oletan, että myös metaforat ovat tässä tehokkaita. Jospa malli on todennut, että sen kannattaa hyödyntää noita kielen mukana siirtyneitä rakenteita tiedon säilyttämiseen (pakkaamiseen) ja siinä liikkumiseen?
(Tässä kohtaa oma mielenikin otti villihkön loikan, ja aloin kuvitella metaforia – etenkin metaforisia verbejä – ikään kuin madonreikinä, joiden kautta pääsee oikaisemaan galaksin toiselle puolelle… tai ainakin toiseen domainiin eli aihepiiriin. Engage!😉 )
Yksi asia johti toiseen, ja pian löysin itseni Neuronpedia-nimiseltä sivustolta kaivelemasta Google DeepMindin Gemma-2-2B-nimisen kielimallin SAE-ominaisuuksia. Ne ovat kielimallin ”apurakenteita”, jotka paljastavat miten malli aktivoituu sanoista ja lauseista – toisin sanoen auttavat ymmärtämään, miten kielimalli ”ajattelee”.
Tätä aktivoitumista voi katsella ja testata Neuronpedian Sparse Auto-Encoder (SAE) -työkalulla, joka on itsessäänkin pieni neuroverkko. Se on kehitetty paljastamaan ja erottamaan kielimallin sisäisiä päällekkäisiä merkityksiä – ikään kuin avaamaan solmuja, joissa useampi ”ajatus” kulkee samaa reittiä pitkin. Tällainen voi olla ongelmallista, jos malli ei kunnolla tunnista, mistä kulloinkin on kyse. Se lisää virheiden ja hallusinoinnin riskiä.
Tuoreessa tutkimuksessa Wang et al. (2025) pyrkivät juuri SAE-tekniikalla parantamaan mallin suorituskykyä. Tässä asetelmassa kielen moniselitteisyys ja metaforat ovat siis ongelma – mallin logiikassa esiintyvä virhe tai häiriö, josta halutaan eroon.
Itse tietenkin olin ja olen kiinnostunut metaforista toisesta näkökulmasta. Vaikka jos mietitään sitä madonreikä-analogiaa, niin onhan se tosiaan ongelmallista, jos päätyykin madonreikään vahingossa eikä toiselle puolelle päädyttyään enää tiedä miten jatkaa!
Käytin Neuronpedian Search by Inference -toimintoa kiinnostavien SAE-ominaisuuksien etsimiseen. Testailin ominaisuuksien aktivoitumista esimerkkilauseilla, joissa sama verbi esiintyy joko konkreettisemmassa tai kuvallisemmassa, vähemmän kirjaimellisessa merkityksessä.
Tässä kohtaa täytyy korostaa, että tämä oli siis aivan ensimmäinen kosketukseni kielimallien mekanistiseen tulkittavuuteen (Mechanistic Interpretability). Opettelin ymmärtämään samalla kuin tein ja jälkikäteenkin. Oppaanani ja tulkkinani tässä toimi Gemini. Toisin sanoen virheitä ja väärinymmärryksiä voi olla, ja alla olevia tulkintoja pitää lukea innokkaan kieli-ihmisen spekulaatioina. Joka tapauksessa tuo kokeilu oli erittäin kiinnostava oppimismatka!
Käytin tällaisia testilauseita nähdäkseni, miten kielimalli aktivoituu flow-verbistä:
- The water flows in the river.
- Money flows into my bank account.
- Information flows through the internet.
- Traffic flows along a city road.
Lisäksi päädyin testailemaan myös travel-verbiä, kun huomasin että valitsemani SAE-ominaisuus aktivoitui myös siitä:
- The train travels across the country.
- Ideas travel across cultures.
- Electricity travels through wires.
- Memory travels back to childhood.
Etsin siis sellaisia SAE-ominaisuuksia, jotka kertoisivat siitä, miten kielimalli käsittelee flow-verbiä tilan muutoksina. Sellaisia löytyikin suht vaivatta. Noita eri esimerkkilauseita testailemalla löysin ja valitsin seuraavat SAE-ominaisuudet. Ne ovat eri kerroksista – transformer-kielimallit käsittelevät informaatiota kerroksittain, ja tiedetään, että käsittelyn abstraktiotaso kasvaa kerrosten myötä.
- Ominaisuus 15915, kerros 19: Actions and processes that indicate movement or physical interaction
- Ominaisuus 16262, kerros 22: Action-oriented verbs related to movement or travel
- Ominaisuus 8561, kerros 23: Actions related to movement and travel
- Ominaisuus 5470, kerros 24: Sequences of actions involving movement or travel
- Ominaisuus 6163, kerros 25: Descriptive actions and movements within a narrative context
Alla olevassa taulukossa on arvot, jotka kuvaavat voimakkuutta, jolla kukin testilause aktivoi kyseisen ominaisuuden.
| SAE Feature / Verb tested | 15915, layer 19 | 16262, layer 22 | 8561, layer 23 | 5470, layer 24 | 6163, layer 25 |
| Water flows | 35,25 | 40,50 | 54,50 | 67,00 | 54,25 |
| Money flows | 36,25 | 0,00 | 20,13 | 33,25 | 27,25 |
| Information flows | 24,88 | 16,25 | 18,63 | 33,50 | 28,25 |
| Traffic flows | 19,88 | 33,25 | 32,25 | 38,75 | 41,00 |
| Train travels | 29,00 | 59,50 | 84,00 | 92,50 | 87,50 |
| Ideas travel | 28,13 | 33,00 | 43,50 | 49,25 | 53,50 |
| Electricity travels | 30,25 | 68,00 | 79,00 | 80,50 | 92,50 |
| Memory travels | 25,38 | 36,25 | 39,00 | 44,25 | 52,00 |
Kerros 19 tunnistaa fysiikan perusvoimat?
Ensimmäinen relevantti kerros tähän testiin tuntui nopeasti katsoen olevan kerros 19, jossa malli käytti SAE-ominaisuutta numero 15915. Sikäli kuin näin pienestä otoksesta voi mitään sanoa, tässä kerroksessa malli näyttää tunnistavan lauseissa liikkeen ja fyysisen vuorovaikutuksen perusvoimat yleisellä tasolla. Konkreettisen ja kuvallisen välillä ei vaikuta olevan eroa aktivoitumisessa.
Lauseet ”Water flows” (35,25) ja ”Money flows” (36,25) aktivoivat tämän Featuren lähes samalla voimakkuudella; samoin ”Train travels” (29,00) ja ”Ideas travel” (28,13). Mallin tulkinta lienee lähinnä: ”Tässä liikkuu jotain, oli se sitten vettä tai valuuttaa, kulkuvälineitä tai informaatiota.”
Lisäksi ”positiiviset logitit” olivat tässä sellaisia kuin back, forward, up, down. Logitit ovat sanoja, joita malli ennustaa seuraavaksi sanaksi. Nuo vahvistavat sitä, että kyse on nimenomaan liikkeestä ja suunnasta.
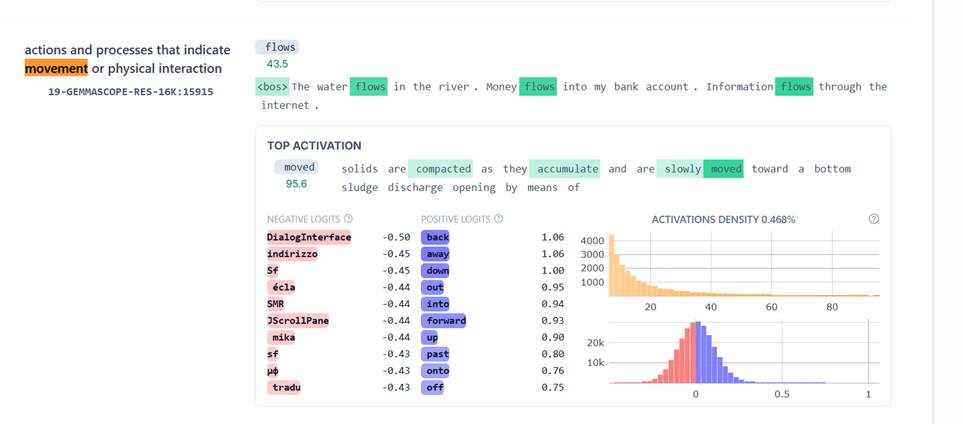
Kuvankaappaus Neuronpediasta. Tämä kuva on kokeilusta, jossa oli useita ”flow”-lauseita samassa. Taulukossa olevat arvot ovat kokeiluista, joissa oli yksi lause kerrallaan.
Ylemmissä kerroksissa malli alkaa erottaa abstraktin ja konkreettisen?
Ylempiin kerroksiin mentäessä näyttää siltä, että konkreettinen tai kirjaimellinen tulkinta aktivoi valitsemani ominaisuuden karkeasti arvioiden kaksinkertaisella voimakkuudella verrattuna abstraktiin tai kuvalliseen tulkintaan. Vahvimmillaan erot ovat kerroksessa 24. Molemmat siis hahmottuvat liikkeeksi, mutta konkreettinen voimakkaammin. Kiinnostavaa!
Yksi hauska sivuhavainto kokeilusta on sähkö. Lause ”Electricity travels” näyttäisi olevan mallille enemmän junan kaltainen (konkreettinen) kuin idean kaltainen (abstrakti). Sähkön aktivoitumisarvot nousevat johdonmukaisesti ja huipentuvat kerroksessa 25 arvoon 92,50 – jopa korkeammalle kuin junalla. Voi siis arvella, että tekoälylle sähkövirta on mitä suurimmassa määrin fyysistä todellisuutta, ei abstraktio.
Kerroksessa 24 Gemini vinkkasi katsomaan myös Logit-kohtaa. Logitit ovat sanoja, joita malli ennustaa seuraavaksi sanaksi. Ominaisuuden 5470 aktivoituessa mallin logitit – eli ennusteet seuraavaksi sanaksi – alkavat painottaa ilmansuuntia: north, south, east, west. Tämä näyttää tapahtuvan jopa silloin, kun lauseen subjekti on abstrakti.
Väistämättä tulee mieleen: voisiko olla mahdollista, että malli käyttää jonkinlaista spatiaalista simulointia hahmottaakseen muutosta myös käsitteellisellä tasolla? Tämä olisi hyvin lakoffilaista: abstrakti ymmärrys rakentuu konkreettisen tilan hahmottamisen päälle. Toki jos nuo ennusteet ovat puhtaasti tilastollisia, tällaista tulkintaa ei niiden perusteella voi tehdä.
Lisäys 6.1. Heti julkaisun jälkeen löysinkin Gurneen ja Tegmarkin tutkimuksen Language Models Represent Space and Time. ”While further investigation is needed, our results suggest modern LLMs learn rich spatiotemporal representations of the real world and possess basic ingredients of a world model.” Eli ainakin konkreettisissa asioissa kielimalli ilmeisesti tekee tuollaista tilallista simulointia.
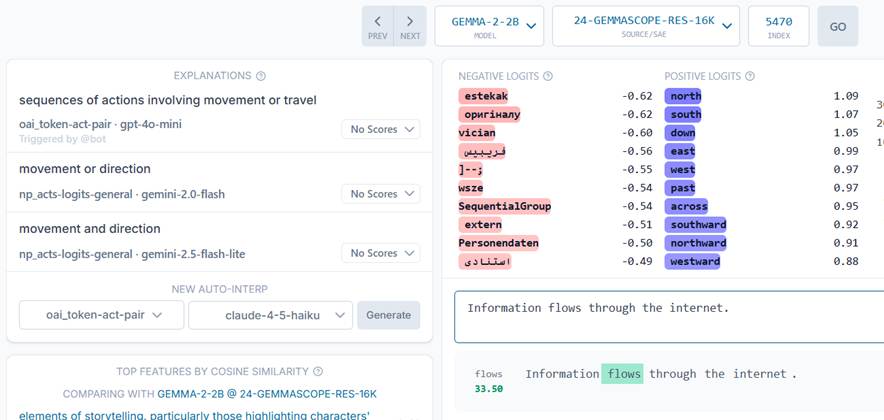
Kuvankaappaus Neuronpediasta. Mallin ennusteet seuraavaksi sanaksi näkyvät violetilla.
Pohdintaa
Kuten sanottua, tässä oli kyse vain kokeilusta. Silti minusta näyttää, ettei SAE-analyysi ole työkalu vain hallusinoinnin vähentämiseen, vaan sillä on potentiaalia paljastaa koneen tapoja jäsentää kieltä ja kieleen sisältyvää maailmaa.
Ehkä tekoäly ei olekaan ”stokastinen papukaija”. Ehkä se on kielen mukana perinyt ainakin osan meidän maailmanmalliamme, jossa sekä fyysiset että abstraktit asiat noudattavat samoja fysiikan lakeja.
En onnistunut löytämään, onko juuri tätä asiaa jo tutkittu noilla työkaluilla. Tiedätkö sinä?
Lisäys 6.1. Nyt löytyi lisää. Tehenan et al osoittavat, että LLM:llä on sisäinen geometrinen representaatio muutoksesta tilassa. Jos siis kielimalli käyttää spatiaalista maailmanmallia konkreettiseen päättelyyn, on perusteltua olettaa, että se saattaa käyttää samaa maailmanmallia myös abstraktien muutosten jäsentämiseen?